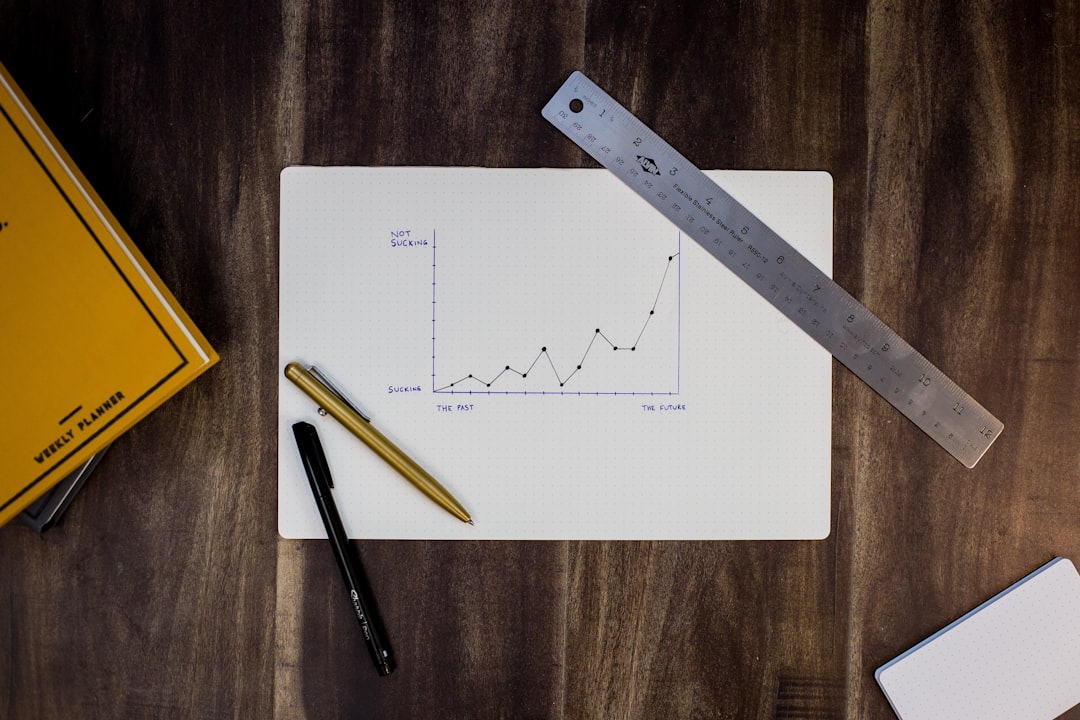
I wanted to get a better sense of where my blog traffic was actually coming from, so I started tracing visitor IPs to their geographic locations.
Using ip-api.com, I queried each IP via: http://ip-api.com/json/{ip} and stored the returned data, including city and coordinates.
As I looked through the results, a pattern started to emerge. A surprisingly large number of requests were resolving to Ashburn, Virginia, United States.
That name kept repeating, and I had not heard much about this city before, so I started digging into what it actually represents.
Data Center Alley
What I found is that Ashburn is not a typical city in the way it appears in analytics. It is better understood as a major physical node of the internet.
Located in Northern Virginia in a region known as "Data Center Alley," it has become one of the most densely concentrated data center hubs in the world. This region is a key global internet and cloud infrastructure exchange point. It is often estimated that around 70% of global internet traffic either passes through or is processed in infrastructure connected to Northern Virginia, not because users are located there, but because major cloud providers and backbone networks operate there.
The area is dominated by server farms, fiber routes, and large-scale networking facilities rather than traditional urban development. This concentration emerged from early internet backbone routing decisions in the United States, strong East Coast connectivity, reliable power, and proximity to Washington D.C., which drove demand for secure infrastructure. Over time, network effects reinforced its role as a global hub.
Today, Ashburn hosts major deployments from:
- Amazon Web Services
- Microsoft Azure
- Google Cloud
- Cloudflare
- Akamai Technologies
Because of this, what appears in logs as "Ashburn traffic" is usually not end users in that location. It is infrastructure traffic generated by systems that sit in front of users: crawlers, CDNs, preview generators, monitoring services, and cloud backend services.
That distinction is important because it changes how meaningful raw analytics data actually is.
Filtering the traffic
Once I understood what was happening, the next step was figuring out how to separate real users from infrastructure traffic more reliably.
Location alone turned out to be a weak signal. A better approach is combining a few simpler layers.
User-Agent filtering A significant portion of automated traffic identifies itself directly. Search engine crawlers, preview bots, and monitoring tools often expose clear user-agent strings, making them easy to classify.
Data center IP ranges Another useful approach is checking whether an IP belongs to a known cloud or hosting provider. There are public IP range lists and datasets available from major cloud providers and security databases that map which IP blocks belong to infrastructure services. This makes it easier to tag traffic as likely data center rather than residential.
CDN headers When using a CDN such as Cloudflare, headers like
CF-Connecting-IPandX-Forwarded-Forcan help recover the original client IP instead of the edge node that handled the request.